_advance_capacity_in_d.tiff)
Air pollution is a significant contributor to the global disease burden,1 responsible for approximately 7 million deaths annually.2,3 The Global Burden of Disease 2019 study estimated that poor air quality contributes 11.3% and 12.2% of deaths of women and men respectively.3–5 According to the World Health Organization (WHO), over 4 million deaths annually are linked to household air pollution, which contributes significantly to the loss of healthy life years.2,6 Individuals with lower income are more likely to reside in areas with higher levels of environmental pollution.2,7–9 Combined with other socioeconomic factors, this contributes to greater disparities in air pollution exposure, health outcomes, and the capacity to manage the impacts of poor air quality.7,10
Fine particulate matter with a diameter of 2.5 micrometers or smaller (PM2.5), is currently the leading environmental cause of morbidity and premature mortality related to lower respiratory infections, with higher exposure rates noted among women and children in both rural and urban African settings.2,11 Air pollution exposure during pregnancy has been associated with increased risks of preterm birth and low birth weight, which are linked to later-life health conditions such as cardiovascular diseases and diabetes.12–15
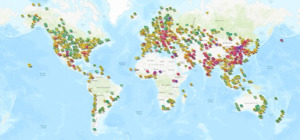
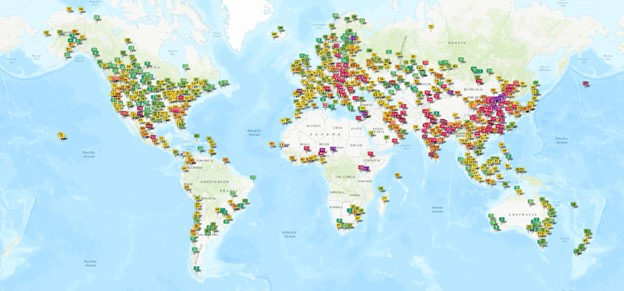
Air quality in sub-Saharan Africa (SSA) has been rapidly declining due to increased urbanization, industrialization, and population growth.1,16 Monitoring air quality is essential for understanding the biological and environmental vulnerabilities of populations, thereby safeguarding human health. In SSA, access to accurate and consistent ground measurements of air pollution is severely limited17 (Figure 1), due to the high costs associated with the necessary infrastructure, equipment, and expertise for maintaining monitoring networks hindering the development of adaptive health interventions.18–20 Alternative air quality indices do however exist to address data scarcity such as the South African Air Quality Index (SAAQI), Kenya Air Quality Index, World AIR Quality Index (WAQI)21–23 among others. However, many of these still have limited spatial and temporal coverage resulting in significant data gaps.24 These indices can enhance air quality assessment when combined with existing measurements, but many pollution exposure proxies still require validation before being applied broadly, especially in SSA.
Our study aims to quantify the current and future effects of air pollution on Maternal Newborn and Child Health (MNCH) outcomes using innovative data science methodologies including machine learning in SSA. Over the past two decades, technological progress has transformed data science into a powerful driver of health research, enabling innovative solutions to major health and societal challenges, particularly in low- and middle-income countries (LMICs).25 In settings often constrained by limited resources and fragile health systems, data science offers tools to enhance surveillance, precision health interventions, and public health planning.25,26
As a multidisciplinary field, data science integrates diverse analytical methods to extract meaningful insights from complex data, supporting evidence-based decision-making, efficient resource use, and improved health outcomes across populations.25 Machine learning has been effectively applied in various medical fields, including disease prediction and forecasting health outcomes such as morbidity and mortality.27 Traditional analytical methods have struggled to handle large and complex healthcare data thereby machine learning techniques, such as random forest, XGBoost, LASSO offer more efficient modeling despite potential biases requiring careful model assessment through standard specification tests.28Literature emphasizes the need for developing appropriate evaluation metrics, generalized and transferable predictive models, and transparency in model selection and outputs within different settings20,29 which our study aims to achieve. The Characterization of Effects of Air Quality on MNCH outcomes (CHEAQI-MNCH) research project focuses on five main objectives (expanded in figure 2):
-
To advance capacity for the application of data science in the field of environmental effects (especially ambient air pollution) on health, focusing on early career individuals and key organizations in SSA.
-
To design air pollution spatial indicators and proxy measures and validate these using ground sensor data.
-
To prepare a data science ecosystem which allows for re-use of existing air pollution, atmospheric, and biomedical data, and serves as a platform for innovative data science analyses.
-
To utilize machine learning approaches to quantify the impact of ambient air pollution on pregnant women and neonates in SSA; and
-
To serve as a continental resource and a center of excellence for knowledge translation, dissemination, and informing policy and practice through engagement and key partnerships.
METHODS
Study design, site, data collection and population
The CHEAQI-MNCH research project is a multi-country study involving retrospective analyses of the association between air quality and MNCH. Using existing data from previous clinical trials, and cohort studies across Africa, the project will characterize air pollution exposures from station, satellite derived and modelled exposure (air pollutants) data. The project takes an opportunity to strengthen research capacity and foster a sustainable data science ecosystem in the design by addressing the existing scarcity of high-quality data and skilled data scientists capable of analysing and disseminating evidence on the health impacts of air pollution in SSA (Figure 2).
_advance_capacity_in_d.tiff)
Enhancing capacity of data science researchers
The project aims to build the capacity of early career researchers in SSA by leveraging on and extending existing skills in data analytics and enhancing their expertise in air quality, atmospheric, health, and data science. Data science enables the processing and analysis of vast datasets generated from patient records, satellite or station data, helping transform fragmented information into actionable evidence through effective data management and analysis making it one of the most valuable fields in health care.30 As the CHEAQI-MNCH research project aims to utilize multidimensional health outcomes and air quality data. graduate and post-doctoral students will receive training in data science including use of machine learning techniques throughout the project phase.
Designing and validation of pollution spatial indicators and proxy measures
CHEAQI-MNCH will leverage existing big geospatial datasets to create high-resolution air pollution geospatial proxy datasets. Satellite products from National Aeronautics and Space Administration (NASA) Earth Data platforms,31 as well as data from sources like the Copernicus Atmosphere Data Store, and local monitoring stations, will be utilized to close data gaps. With the use of large air quality datasets, modelling of atmospheric systems that are highly dynamic, geographically extensive, and exhibit diverse heterogeneity can be conducted, enhancing the reliability of results.32
Exposure estimation and predictive modelling will be supported by machine learning algorithms such as random forests and gradient boosting.33 Hierarchical clustering will be applied to detect spatial and temporal patterns within the exposure data. Additionally, spatiotemporal modelling techniques will be applied to produce high-resolution pollution geospatial datasets and to examine variability across different regions and seasons.33 Multilevel clustering and spatio-temporal profiling will be used for feature engineering.
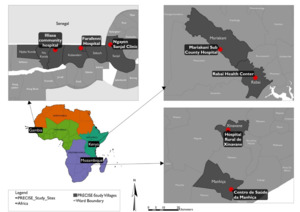
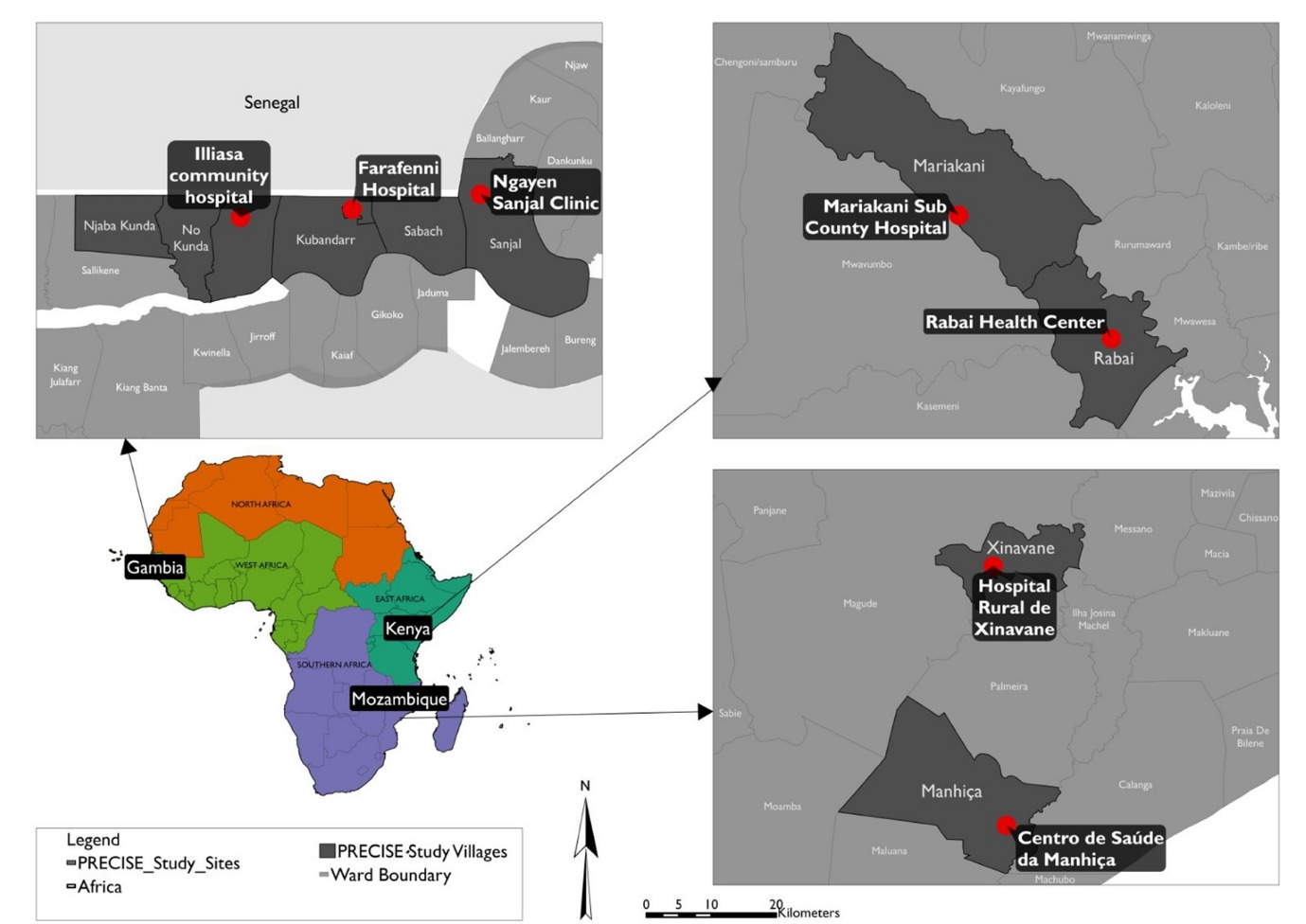
A high resolution ((1,048,576 data points) Personal pollution exposure data collected by 343 post-partum women from the PREgnancy Care Integrating translational Science Everywhere (PRECISE) study over 11 months (2022–2023).The data was collected using low-cost monitors with GPS tracking recorded PM2.5, NO2, humidity, and temperature at second-level intervals, both indoor and outdoor across the different seasons in the study sites.34The outdoor sub dataset will be will be used to design and validate pollution indices that relate closely to pollutants, including PM10, PM2.5, Nitrogen Dioxide (NO2). The PRECISE study was conducted in Kenya, The Gambia and Mozambique (Figure 3). The PRECISE women were provided with low-cost personal exposure monitors that measured air quality in the different micro-environments where the participants spent their time over varying seasons.
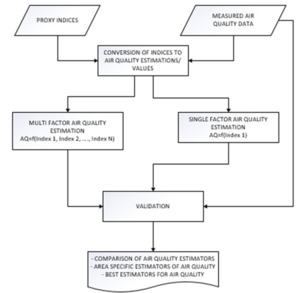
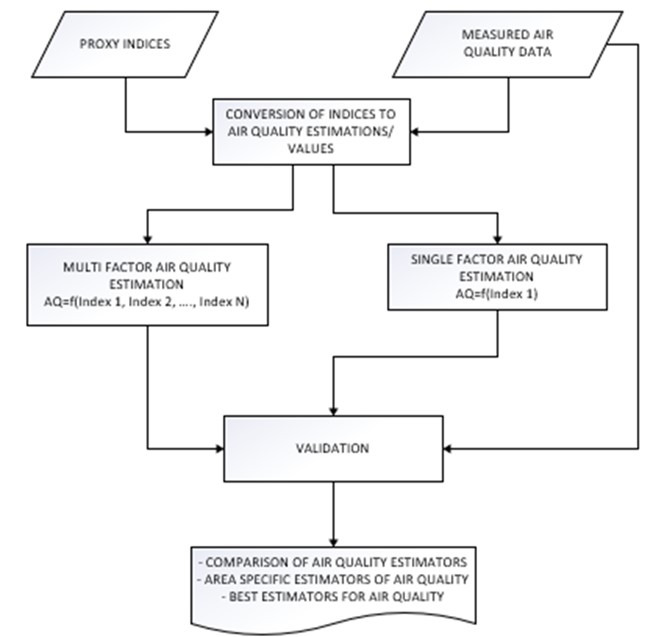
New geospatial pollution proxies will be developed and tested to address the limitations of current measures. A comparative analysis will be conducted between proxy indicators and personal exposure data. Validation of the indices’ predictive performance will be tested using methods including general linear regression, correlation hotspot analysis, machine learning regression Static proxies to be validated will include Euclidian distance from highways, Euclidian distance from main roads and population weighted road network density while dynamic proxies will include Normalized Difference Vegetation Index (NDVI) and Aerosol Optical Depth (AOD). The most reliable proxies will be identified and upscaled using GeoAI to map exposure across SSA (Figure 4). This will include incorporating climate variables to produce a forecast relevant pollution probability scores.
The study will use GeoAI techniques to perform data mining, and modelling using different algorithms such as recurrent neural networks, random forest models,35 GeoAI will be utilized during the modelling phase because its captures air pollution modelling concerns i.e nonlinearity, complexity and dynamic nature of pollution proxies. These models can integrate multiple input data enhancing input data. Additionally, these models address concerns of spatial autocorrelation within the input datasets and will be accounted during the model build up. Common evaluation metrics like Root Mean Square Error, f-measure, and Area Under the Curve (AUC) will be tested, and new metrics may be developed, if needed. GeoAI will enable scalable platforms for managing health and geospatial data, extracting actionable insights, and modeling environmental exposures across regions.36 By leveraging big data infrastructure and open-source frameworks, GeoAI will help model pollution exposure and other geospatial proxies, providing insights into the degree, duration, and impact of ambient air pollution at specific times and locations.
Development of a data science ecosystem
CHEAQI-MNCH will create a federated data infrastructure to improve its capacity for managing and analysing large datasets. Data security is a top priority, involving access control, user agreements, and policies governing data access and retention.37 This infrastructure strengthens collaboration within the research project on how research partners can share and access different datasets protecting privacy and adhering to ethical obligations. This infrastructure will adhere to data access control through implementation of strong user authentication such as password security, API key management, and account recovery, while access will be role-based. The facility will offer data storage and operational needs, with critical datasets backed up across multiple sites.38 The federated data infrastructure will serve as a learning resource and platform for making air pollution data open. This will promote FAIR data use and promote open science.
Quantifying the impact of air pollution on MNCH outcomes
The PRECISE study will serve as pilot analysis for air pollution and MNVCH interaction is the 3 countries representing all 3 regions of SSA (West, East and Southern Africa). In addition to the personal exposure air quality data, PRECISE collected data on socio-geographic and demographic data, and MNCH outcomes from 6,933 women that will be used for analyses in the project.34,39 As a second step, CHEAQI-MNCH will also use data on MNCH outcomes from the Heat Health African Transdisciplinary Center (HE2AT Center) Individual Participant Data (IPD) meta-analysis dataset.40 The HE2AT Center is harmonizing approximately 2.2 million MNCH individual participant records from 223 clinical trials and cohort studies across 33 SSA countries for the purpose of rapidly generating evidence on the impacts of exposure to extreme heat on the health outcomes of pregnant women and their babies.40 The MNCH outcomes collected include preterm births, low birth weight, congenital abnormalities, respiratory tract infections, pre-eclampsia/eclampsia, and others. The use of large datasets enhances the ability to explore research questions often overlooked by experimental studies providing the ability for robust analyses.41 They also improve statistical power, enabling accuracy to assess effect direction and magnitude, examine variations in outcomes, and study the antecedents of rare yet impactful phenotypes, which can lead to novel interventions.35,41
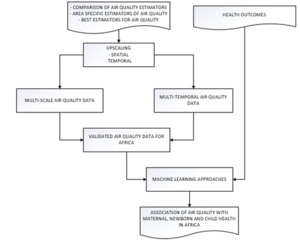
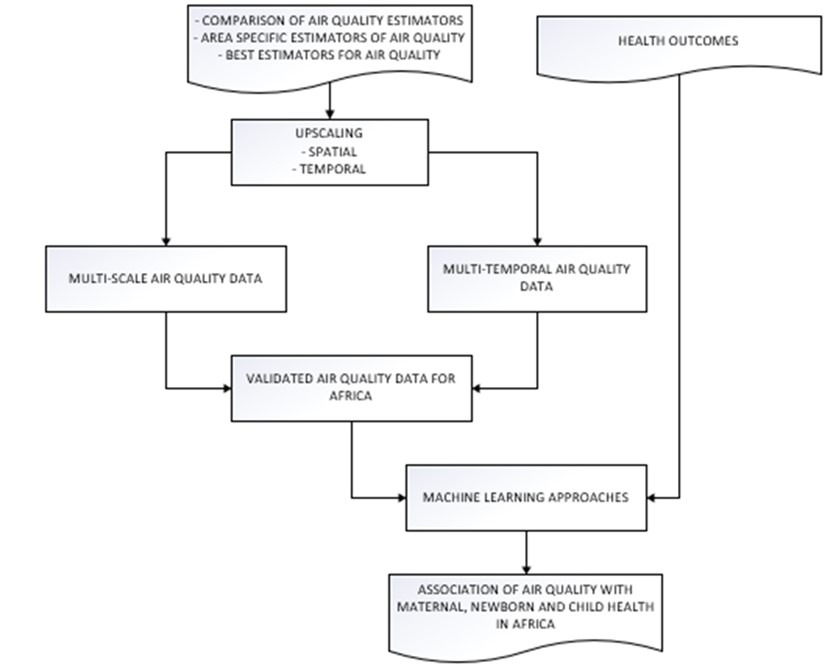
The study will use predictive models that capture spatial-temporal nonlinearity and complexity of relationships that affect air pollution and health outcomes modelling in SSA. These include random forest, XGBoost and LASSO regression. Rigorous validation will be done to remove bias of machine learning models. Figure 5 summarizes linking of exposure with health outcomes using machine learning.
Translation of evidence and dissemination
Translating and disseminating evidence on the impacts of air pollution on MNCH is crucial for reducing the burden of pollution related health conditions. There is growing pressure to rapidly translate research into practice and demonstrate real-world benefits, making it essential to develop new ways to capture the broader impacts of research, even when these impacts are difficult to measure.42 Translation and dissemination of scientific results is equally important to non-academic stakeholders who play a key role in decision-making and in reducing health impacts.42
Existing tools struggle to address individual-level exposure and are difficult to scale across different regions. With big spatial datasets and machine learning approaches, there is an opportunity to create scalable, context-specific intervention tools tailored to MNCH. The tools will account for geographic inequities and the varying factors influencing pollution exposure across urban and rural areas. A location-sensitive early warning system will be implemented through the integration of personal pollution exposure model, real-time air quality monitoring, and health information systems. The system will aggregate data from satellite observations, ground-based sensors, and modelled estimates to generate dynamic pollution maps and predict high-risk zones beginning with experimental observations in Zimbabwe in partnership with the Ministry of Environment. Using open APIs, it will interface with electronic health records (EHRs) to enable targeted alerts for vulnerable populations, particularly pregnant women, based on their location and pregnancy stage. Policymakers and citizens will receive real-time notifications through digital platforms and mobile communication channels, supporting timely interventions and evidence-based decision-making. Designed as an open-source, modular platform, the system will facilitate scalability and integration with national health and environmental infrastructures in SSA.
Research findings will be shared through scholarly publications, presentations at conferences, educational materials, and outreach activities like workshops and seminars conducted with health professionals and policy makers. Intercountry planning and dissemination meetings with stakeholders including data providers will be organized ensuring inclusion, shared insights and ownership of interventions. Engagement and sharing of results will be implemented in partnership with policymakers through policy briefs to the public and research community. The project will ensure at least 3 press releases, and open-air interviews with the public to ensure participation. This approach will maximize the research’s visibility and impact, supporting ongoing efforts to improve MNCH.
DISCUSSION
Understanding the effects of air pollution on MNCH outcomes is a critical scientific priority, as exposure to polluted air has been consistently associated with adverse pregnancy outcomes, impaired fetal development, and increased infant morbidity and mortality. Quantifying these effects provides essential evidence for developing targeted public health interventions, informing environmental policies, and mitigating long-term health risks across vulnerable populations. According to evidence, the area remains underexplored in SSA because of lack of monitoring stations43 which is a public health concern in SSA.
Through the development and validation of air quality proxies, this study will establish cost-effective and scalable approaches for estimating air pollution exposure and spatial–temporal patterns, particularly in SSA where air quality monitoring remains limited or absent in many regions. These methods will enhance the accuracy of exposure assessment and support health risk assessment and policy development across data-scarce settings. Previous studies have highlighted the limited data science workforce in SSA and the absence of centralized platforms for accessing air pollution datasets essential for quantifying health effects.17,25 Building on this context, the present study seeks to strengthen the regional data science ecosystem by developing local expertise and integrated data infrastructures. This initiative will facilitate easier access to air pollution and MNCH datasets while promoting knowledge sharing and collaborative research on the health impacts of air pollution across the region. Machine learning approaches within the broader framework of data science enable the prediction of future health outcomes by modeling complex relationships between environmental exposures and vulnerable populations.27,28 For instance, these methods can forecast how increasing PM2.5 concentrations may impact the health of pregnant women and infants. Such insights require the integration of diverse machine learning models, each leveraging its predictive strengths to enhance understanding of the associations between air pollution and MNCH outcomes and thereby informing policy and WHO guidelines in promoting health. This does not diminish the value of traditional statistical methods, which remain essential for characterizing relationships between exposures and health outcomes. However, these methods have demonstrated limitations in processing and analyzing large, complex data sets,28 an increasingly critical requirement for accurately assessing the impacts of environmental variables on health outcomes.
However, the research project anticipates challenges due to the limited number of air quality monitoring stations in Africa, which may hinder the acquisition of sufficiently high-resolution data for model development and validation. Hence the research will seek to intensify the research in the regions that have existing air quality data and then test for model performance .Whilst this approach may pose challenges on overfitting or underfitting , during the model development several models which are spatiotemporal intelligent will be developed and tested for sensitivity in different scenarios, hence the proposed approach of starting with 3 PRECISE sites that are a representative from the different sections of SSA and the availability of the multidimensional big data collected during PRECISE study period. . Additionally, delay in obtaining MNCH data poses another challenge, especially with necessary data transfer agreements required to access health outcomes data provided on time. Another limitation would be the predictive validity of proxy indicators and their correlation with true measurements which could affect the validity of the results and their potential for upscaling. For example, if the proxy indicators do not show statistically significant effects on air quality, the feasibility of upscaling the findings may be questioned.
CONCLUSIONS
This study advances understanding of the health impacts of air pollution on MNCH in SSA by integrating data science and machine learning approaches. Through the development and validation of air quality proxy indicators, it establishes cost-effective and scalable methods for exposure estimation in regions with limited monitoring infrastructure. The project also contributes to strengthening the regional data science ecosystem by building analytical capacity and promoting accessible, harmonized datasets. While challenges such as limited monitoring coverage and predictive uncertainty of proxies are anticipated, the study’s multi-model and spatiotemporal framework ensure methodological robustness. Ultimately, the findings will generate actionable evidence to inform environmental health policy, guide WHO-aligned interventions, and support efforts to protect vulnerable populations, particularly pregnant women and infants from pollution-related health risks.
Disclaimer
This manuscript offers an accurate, transparent, and comprehensive representation of the research project, ensuring that all essential aspects are included.
Ethics statement
The study received approval from Midland State University Ethics Committee in Zimbabwe (ref FBEAD/001/2025) (S1). The MSU has secured permission to use the PRECISE data and will implement the objectives alongside the Centre for Sexual Health and HIV/AIDS Research (CeSHHAR) in Zimbabwe. This study will be conducted in compliance with International Good Clinical Practices (GCP), the ethical principles outlined in the Declaration of Helsinki, and relevant regulatory requirements. All the research project team members have received training on GCP ensuring the rights, safety and well-being of participants are protected, including use of credible and reliable data. The project adheres to national, regional, and global ethical standards in medical research ensuring that all data sources comply with regulations such as the ten principles of the Nuremberg Code regarding research on human subjects. Following the 32 principles of the Helsinki Declaration, the project will make sure all participants signed the informed consent from the studies used. The study will also make certain confidentiality, and the protection of vulnerable populations from harm was followed by the studies by requesting the study protocols including verification of the processes together with study teams and principal investigators. The project will access de-identified data to protect privacy and prevent potential harm. Data access agreements will be designed, shared and signed between study groups such as the PRECISE study project network, the HE2AT Center and CHEAQI-MNCH for utilization of data for analyses and ensure the data management processes by management teams are supervised by all parties timely throughout the study phase
Data availability
Models, research outputs, and data science approaches from the CHEAQI-MNCH research project will be shared with the Data Science for Health Discovery and Innovation in Africa (DS-I Africa) network and the public according to National Institutes of Health (NIH) guidelines, with a focus on protecting vulnerable populations. A data access committee, including a bioethics expert, will oversee data sharing procedures, ensuring transparency and security while expediting requests for researchers exploring different questions.
Funding
Research is supported by the Fogarty International Center and National Institute of Environmental Health Sciences (NIEHS) and OD/Office of Strategic Coordination (OSC) of the National Institutes of Health under Award Number U01 ES036146-01. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health. The PRECISE Network is funded by the UK Research and Innovation Grand Challenges Research Fund GROW Award scheme (grant number: MR/P027938/1).
Authorship contributions
PTM and TG are the principal investigators of this project. LM, TDM, HBN were involved in drafting the manuscript, and the final draft and write up was done by LM. Contributions to the final manuscript have been made by all authors. LM accepts full responsibility for the finished work of the manuscript, with all authors taking responsibility for the decision to publish.
Disclosure of interest
The authors completed the ICMJE Disclosure of Interest Form (available upon request from the corresponding author) and disclose no relevant interests / declare the following activities and relationships.
Correspondence to:
Laura Munthali
Centre for Sexual Health and HIV/AIDS Research
Number 10 Coronation Ave, Greendale, Harare
Zimbabwe
laura.munthali@ceshhar.org, lmunthali@mlw.mw